Podložíme zase nějakým podkresem, pravým analogovým.
Víme nespolehlivost kanálu – pravděpodobnost chybného bitu – a z toho programem GNU R spočteme jak silný ten šumový signál je.
> help(qnorm)
qnorm je kvantilová funkce normálního rozložení. Té se dá pravděpodobnost a ona nám řekne, v jaké vzdálenosti od středu šumu musí být řezací úroveň, aby pod ní šum lezl s danou pravděpodobností. Protože jde o poměr mezi řezací úrovní, která je fixní, a šířkou kopečku, přidáme před to 1/ (jedna lomeno). Mínus je, protože nás zajímá lezení šumu nad řezací úroveň místo pod ni. A nakonec vydělíme 2, protože řezací úroveň je v půlce mezi hodnotami bitu 0 a 1:
> sirka=-1/qnorm(0.001)/2 > sirka [1] 0.1618001 > plot(x,dnorm(x, mean=0,sd=sirka),type="l") > lines(x,dnorm(x, mean=1,sd=sirka),type="l")
Co je na obrázku? Levá křivka reprezentuje histogram signálu přijatého pro nulové vyslané bity a ta pravá pro jedničkové. Malinkatý zářez – zobáček nad hodnotou 0,5 představuje právě tu malinkatou plochu, kde je pokrytí dvojnásobné a vznikají chyby. Ten zbytek se přijme bezchybně.
Větší šum by odpovídal širším, více se překrývajícím kopečkům. Nižší zase užším, které by se pochopitelně méně překrývaly. Kdyby kanál byl úplně bez šumu, měli bychom jen dvě svislé, nekonečně vysoké spektrální čáry – nuly a jedničky, přesně stejné hodnoty, co jsme vyslali. Takhle se nám hodnoty různě posouvají od čísel 0 a 1 podle toho, kterým směrem s nimi šum zrovna hne.
Takto si teď situaci nasimulujeme. Předpokládám, že počet nul a jedniček na vysílači je zhruba stejný (pro běžné obrázky typicky splněno). Také předpokládám, že síla šumu je stále stejná, konstantní, ta, kterou jsme vypočítali. Ona konstantní typicky bude, určená fyzikálními parametry, v případě tisku na papír vlastnostmi toneru a papíru a tiskového procesu. V případě elektronického systému je daná silou temodynamického šumu na odporech v obvodu, výstřelového šumu na polovodičových přechodech, kterými protéká proud. V případě mozku to budou procesy teplotního šumu a šum tvořený kvantizací (diskrétním charakterem) aktivních molekul a diskretizací nervových impulsů. Typicky se v mozku jako analogová hodnota bere průměrný počet impulsů za určitý časový interval.
Další zjednodušení, co tu mám, že šum je aditivní – k signálu se přičítá. V elektronice to tak typicky je, u tisku ne. Síla šumu může záviset na přenášené hodnotě. Jak je to v mozku, přesně nevím. Domnívám se že toto omezení modelu zde nemá podstatný význam. Dá se snadno kompenzovat tím, že signálové hodnoty natáhneme nebo smáčkneme tak, aby při přenosu trpěly všechny stejně.
Podle Bayesovy věty je pak pravděpodobnost, že byl bit 1, jaká? Je to pravděpodobnost, že jedničkový bit vygeneruje přijatou hodnotu, vydělená pravděpodobností, že vůbec nějaký bit vygeneruje přijatou hodnotu:
gmic wat.pnm -div 3 -round -o wat_msb.pnm -noise 0.162,0 [0] -sub[1] 1 -div 0.162 -pow 2 -div -2 -exp -add[0] [1] -div[1] [0] -remove[0] -o gmic wat.pnm -mod 2 -o wat_lsb.pnm -noise 0.162,0 [0] -sub[1] 1 -div 0.162 -pow 2 -div -2 -exp -add[0] [1] -div[1] [0] -remove[0] -o gmic -mul 2 -add -mul 85 -cut 0,255 -o result_bayes.png -d
V gmicu na konci vidíme, že výsledný obrázek obsahuje desetinné pixelové hodnoty (při pohybu myší po obrázku).
Další možnost, jak kvalitu zlepšit, by byla založená na tom, že poškozený horní bit nadělá větší paseku než poškozený dolní bit. Napartitionovali bychom tedy bity na papíře tak, že by MSB byly fyzicky větší, a měly tím pádem lepší odstup od šumu a menší pravděpodobnost chyby.
Je v jednoduchosti genialita?
Co se ale místo stále sofistikovanějšího postupu ukládání bitů na papír a komplexního dekódování se statistickými algoritmy pustit opačným směrem? Nešlo by se inspirovat heslem „v jednoduchosti je genialita“? Co ten obrázek na ten papír prostě vytisknout? Je třeba ho rozložit do R G a B kanálů a přidat nějaké soutiskové kříže, aby fotografie nevypadala, jako když se Sergejovi Michajloviči Prokudinovi-Gorskému pohne jeho subjekt:
gmic "(0,255;255,0)" -to_rgb wat.png -resize[0] 10,[1] [0] -append x [0] [0] -channels[0] 0 -channels[1] 1 -channels[2] 2 -o[0] red.png -o[1] green.png -o[2] blue.png -append y
Nascanovaný tisk pak nahrajeme do GIMPu a pomocí funkce perspective transform – corrective (písmeno p) registrujeme soutiskové značky na rohy obrazu. Při složení jsem pak udělal nějakou korekci na černou, která není úplně černá, a korekci nelinearity polotónovaného tisku tiskárny:
gmic red.png green.png blue.png -sub 15 -mul 1.0625 -div 255 -pow 1.5 -mul 255 -append c with_sync.png -resize[0] [1],5 -remove[1] -cut 0,255 -o result_analog.png -d
Musím říct, že kvalita tohoto analogového nekomprimovaného obrazu mě proti těm nekomprimovaným digitálním velmi překvapila. Obraz vnímám jako překvapivě čistý s mnohem lepší reprodukcí barevných gradací, a charakter rušení vnímám jako méně obtěžující, přirozenější, prostě analogový :).
Na analogovém kanálu by JPEG vůbec z principu běžet nemohl, ale jak by si vedl na chybovém digitálním kanále? Na bezchybném digitálním kanále má 100 kB JPEG obrazovou kvalitu velmi vysokou:
Zdroj (GFDL): D.Alyoshin, Wikimedia Commons
JPEG na chybovém kanále
Při naší příkladové chybovosti 0,1 % je JPEG zcela nepoužitelný:
Jak si vede při různých chybovostech od 2-10 do 2-18 , můžete vidět v galerii. Některé pokusy tam chybí, to je když JPEG zchátral natolik, že ho ani GMIC nedokázal načíst, aby ho znovu korektně uložil.
Sečteme-li všechny chybové obrázky v galerii, vyjde obrázek rozeznatelný jen v hrubých obrysech – jakási Praha stověžatá. Reakce tohoto digitálního systému na chyby má následující vlastnosti:
Poškozuje se víc dolní část obrázku
Vznikají geometrické struktury, co tam vůbec nebyly (šachovnice, proužky)
Dochází k prostorovým posuvům
Jedna chyba dokáže poškodit velké části obrázku
Dochází k totálním výpadkům částí obrazu
Integrací více snímků nelze kvalitu zlepšit, naopak, obraz se rozmaže.
V příštím díle uzavřu srovnání analogových a digitálních metod a konečně už vezmeme svěrák, pilku na železo, meotar a osciloskop a podíváme se fyzicky, co pod kapotou běhá za signály.
Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Ukládání a komprese obrazu Pavel Strachota FJFI ČVUT v Praze 22. ledna 2015 Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Obsah 1 Úvod 2 Reprezentace barvy 3 Kódování a komprese dat 4 Formáty pro ukládání obrazu 5 Komprese videa Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Obsah 1 Úvod 2 Reprezentace barvy 3 Kódování a komprese dat 4 Formáty pro ukládání obrazu 5 Komprese videa Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Reprezentace obrazu vektorová - popis geometrických objektů a jejich vlastností (polohy, barvy, překrývání atd.) nezávisí na rozlišení zobrazovacího zařízení lze libovnolně škálovat při zachování kvality rastrová - popis obrazu pomocí matice pixelů konečné rozlišení vysoká pamět’ová náročnost =⇒ snaha o kompresi informace Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Obsah 1 Úvod 2 Reprezentace barvy 3 Kódování a komprese dat 4 Formáty pro ukládání obrazu 5 Komprese videa Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Reprezentace barvy černobílý obraz - 1 bit na pixel šedotónový obraz - 8 bitů na pixel, 256 stupňů šedi RGB reprezentace 5+6+5 bitů (565 High Color mode) 8+8+8 bitů True Color mode reprezentace v jiném barevném prostoru (viz dále) indexovaná barva - ukládá se index do palety paleta pevně daná (např. standardní VGA paleta) adaptivní (vhodně přizpůsobená obrázku, uložená v souboru spolu s obrázkem) typicky 4, 16, 256 barev Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Použití pevné palety barvy reprezentovány body v 3D prostoru RGB nebo jiném často se používá L∗ a∗ b∗ (CIELAB 1976) problém: každému pixelu o obecné barvě přiřadit barvu z palety paleta n barev o složkách [Ri , Gi , Bi ] vzdálenost barev měříme euklidovskou mírou barvu [R, G, B] nahradíme barvou palety s indexem q argmin (R − Ri )2 + (G − Gi )2 + (B − Bi )2 i∈Nn oblasti prostoru RGB nahrazené i-tou barvou palety jsou Voroného diagramy (viz výpočetní geometrie) Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Tvorba adaptivní palety kvantizace barev pomocí algoritmů pro shlukování (clustering) bodů v 3D prostoru body v prostoru = množina všech barev obsažených v obrázku Vektorová kvantizace k -means 1 2 Spustit demo náhodně umísti k tzv. centroidů do prostoru (budoucí barvy palety) ∀i ∈ {1, 2, . . . , k } najdi množiny bodů Mi , kterým je nejblíže i-tý centroid 3 ∀i přemísti i-tý centroid do těžiště množiny Mi 4 pokud se alespoň jeden centroid pohnul, jdi na 2 náhodná inicializace nemusí vždycky zafungovat (centroid zůstane „sám") k -means++ : lepší algoritmus pro inicializaci k -means Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Tvorba adaptivní palety kvantizace barev pomocí algoritmů pro shlukování (clustering) bodů v 3D prostoru body v prostoru = množina všech barev obsažených v obrázku Vektorová kvantizace k -means 1 2 Spustit demo náhodně umísti k tzv. centroidů do prostoru (budoucí barvy palety) ∀i ∈ {1, 2, . . . , k } najdi množiny bodů Mi , kterým je nejblíže i-tý centroid 3 ∀i přemísti i-tý centroid do těžiště množiny Mi 4 pokud se alespoň jeden centroid pohnul, jdi na 2 náhodná inicializace nemusí vždycky zafungovat (centroid zůstane „sám") k -means++ : lepší algoritmus pro inicializaci k -means Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Tvorba adaptivní palety kvantizace barev pomocí algoritmů pro shlukování (clustering) bodů v 3D prostoru body v prostoru = množina všech barev obsažených v obrázku Algoritmus median cut 1 začni s jedním kvádrem obsahujícím všechny body 2 rozděl kvádr s absolutně nejdelší stranou podél této strany na 2 části tak, aby v každé ležela polovina bodů ( =⇒ hledání mediánu) 3 vzniklé poloviny kvádru zmenši co nejvíce, aby se do nich ještě vešly dané body 4 pokud je počet kvádrů menší než velikost palety n, jdi na 2 5 i-tá barva palety se najde např. jako průměr, resp. medián bodů v i-tém kvádru Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Adaptivní paleta Originál Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Adaptivní paleta Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Adaptivní paleta VGA paleta Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Adaptivní paleta Originál Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Adaptivní paleta Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Adaptivní paleta VGA paleta Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Adaptivní paleta Originál Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Adaptivní paleta Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Adaptivní paleta VGA paleta Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Obsah 1 Úvod 2 Reprezentace barvy 3 Kódování a komprese dat 4 Formáty pro ukládání obrazu 5 Komprese videa Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Komprese dat snaha najít co nejúspornější zápis pro nějakou zprávu sekvence znaků (bytů) zapsány pomocí jiných, pokud možno kratších sekvencí =⇒ kódování efektivita komprese závislá na povaze zpracovávaných dat bezztrátová komprese (lossless compression) aplikovatelná na libovolná data možnost přesně rekonstruovat původní zprávu ztrátová komprese (lossy compression) lze použít jen na subjektivně vnímaná data (obraz, video, zvuk) možnost rekonstruovat původní zprávu jen přibližně využití znalosti lidského vnímání =⇒ efektivní komprese při zachování malého subjektivně vnímaného rozdílu mezi původní a rekonstruovanou zprávou Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Kódování RLE Run-Length Encoding jednoduchá metoda efektivní pro obrázky s oblastmi vyplněnými stejnou barvou posloupnost opakujících se bytů (resp. dvojic, trojic bytů) nahradí jednou hodnotou s uvedením počtu opakování zápis 7-bitové hodnoty 0 value 1 0000000 value zápis hodnoty ≥ 100000002 1 counter value zápis hodnoty opakující se (1 + counter)-krát pokud se v sousedních pixelech ve směru ukládání (obvykle po řádcích) často neopakují stejné hodnoty =⇒ záporná komprese (výsledek delší než originál) Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Huffmanovo kódování statistická metoda teoretický zdroj informace generující konečný počet zpráv se známým rozdělením pravděpodobnosti kódování celých zpráv D-znakovými kódovými slovy (obsahujícími znaky 0, 1, 2, . . . , D − 1) nejpravděpodobnější zprávy kódovány nejkratšími kódy a naopak Huffmanův kód je optimální (minimalizující střední délku kódu) mezi instantními jednoznačně dekódovatelnými kódy instantní kód = kódové slovo žádné zprávy není prefixem kódového slova jiné zprávy postupně procházíme sekvenci znaků jakmile narazíme na řetězec, který je kódovým slovem, lze ihned dekódovat nejčastěji binární Huffmanův kód (D = 2) Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Huffmanovo kódování Konstrukce kódu původně n různých samostatných (jednoduchých) zpráv pracujeme se sdruženými zprávami = množinami zpráv každé jednoduché zprávě odpovídá kódové slovo přiřadit sdružené zprávě M kódový znak = přidat jej na začátek kódových slov všech jednoduchých zpráv v M Algoritmus 1 zpočátku n samostatných zpráv 2 seřad’ zprávy podle pravděpodobnosti 3 vyber D zpráv s nejnižší pravděpodobností a přiřad’ jim kódové znaky 0, 1, 2, . . . , D − 1 4 tyto zprávy spoj do sdružené zprávy s pravděpodobností danou součtem pravděpodobností původních zpráv 5 dokud existuje více než 1 zpráva, jdi na 2 Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Huffmanovo kódování Binární kód a jeho reprezentace binárním stromem binární kód =⇒ v každé iteraci spojíme vždy 2 zprávy spojování zpráv = vytváření binárního stromu „odspodu“ od listů uzel - sdružená zpráva jeho potomci - zprávy, z nichž vznikl levému potomku přiřazen kódový znak 0, pravému potomku znak 1 listy - jednoduché zprávy dekódování zprávy - procházení stromem od kořene doleva, resp. doprava, pokud ze vstupu čteme 0, resp. 1, až dojdeme k listu Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Huffmanovo kódování Binární kód a jeho reprezentace binárním stromem 3 zprávy A,B,C Zpráva A B C Pravděpodobnost 0.6 0.3 0.1 Kód 0 10 11 nelze např. aby zpráva B měla kódové slovo jen „1“, protože výsledný kód by nebyl instantní („1“ je prefixem „11“) Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Huffmanovo kódování v praxi 1/3 zprávy - sekvence bitů v obrázku, resp. obecných datech jejich pravděpodobnosti odhadnuty (napevno určeny) statistickým zpracováním typických dokumentů standardy CCITT (Comité Consultatif International Téléphonique et Télégraphique) původně pro přenos černobílých dokumentů faxem Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Huffmanovo kódování v praxi 2/3 standard G31D (group 3 1-dimensional): zakódování pomocí RLE → hodnoty čítače opakování kódovány dále pomocí Huffmanova kódu krátké kódy pro typické úseky bílých, resp. černých pixelů a dále: kód FILL (stejná barva až do konce řádku) kód EOL (konec řádku) =⇒ synchronizace, odolnost proti chybám kód RTC (return to control) - konec dat možno dekódovat bez vyrovnávací paměti Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Huffmanovo kódování v praxi 2/3 standard G32D (group 3 2-dimensional): kódování pozic změny barvy, relativně vůči předchozí pozici uvažuje se i změna oproti předchozímu řádku (ve vertikálním směru) každý K -tý řádek se kóduje pomocí G31D kvůli spolehlivosti mnoho detailů a ošetření chyb při přenosu standard G42D (group 4 2-dimensional): v podstatě G32D bez mechanismů odstraňování chyb použití ve formátu TIFF Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Kódování LZW Lempel-Ziv-Welch, 1984 odvozeno od LZ77 (Jakob Ziv, Abraham Lempel, 1977) metoda vhodná pro zcela obecná data implementovaná v programu compress a ve formátu GIF snaha efektivně komprimovat data, kde neznáme pravděpodobnost zpráv (např. symbolů atd.) princip: slovníkové kódování (dictionary based encoding) Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Kódování LZW Princip metody 1/3 slovník mapující bitové kódy na řetězce bytů (slova) slovník se tvoří dynamicky ze vstupních dat kódy mají délku 9-12 bitů (max. 212 = 4096 položek slovníku) komprimovaný soubor je posloupnost bitových kódů (přes hranice bytů) na počátku je délka kódu 9 bitů, slovník obsahuje 258 položek prvních 256 položek (kódy 0 − 255) jsou jednobytové „řetězce“ (kód se shoduje s 1-bytovou hodnotou) kód 256 je „clear code“ - kód pro vyprázdnění slovníku kód 257 je „end of data“ Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Kódování LZW Princip metody 2/3 Algoritmus komprese LZW 1 w = ∅ (prázdné slovo) 2 načti znak K ze vstupu 3 pokud je wK ve slovníku, proved’ wK → w 4 jakmile wK není ve slovníku: vypiš na výstup kód C slova w wK přidej do slovníku pod novým kódem K →w 5 jdi na 2 pokud v bodu 4 nestačí délka kódu, zvýší se o 1 bit, max. však na 12 bitů když se slovník zaplní, vyprázdní se (až na prvních 258 položek), vypíšeme clear code a začneme od začátku Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Kódování LZW Princip metody 3/3 slovník není obsažen v komprimovaných datech, při dekompresi jej lze rekonstruovat právě při dekompresi je potřeba clear code při kompresi se kód na výstupu objevil vždy spolu s novým zápisem do slovníku totéž se bude dít při dekompresi délka kódu (kolik bitů číst ze vstupu) se bude automaticky řídit délkou slovníku (v následujícím se délkou kódu ani vyprázdněním slovníku nezabýváme) Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Kódování LZW Princip metody 3/3 Myšlenkový postup dekomprese LZW 1 načti kód C ze vstupu 2 první kód určitě ve slovníku je 3 vypiš na výstup odpovídající slovo w vím, že enkodér vypsal C, protože narazil na takový znak K , že wK nebylo ve slovníku (a wK zařadil do slovníku) znak K ještě neznám, ale je to první znak slova, které kóduje následující kód =⇒ příště zjisti K a slovo wK zařad’ do slovníku pod novým kódem. 4 jestliže však příští kód není ve slovníku: vím, že enkodér musel tento kód právě vygenerovat =⇒ je to kód odpovídající slovu wK a tedy K je zároveň prvním znakem w přidej wK do slovníku pod tímto kódem, wK → w a jdi na 3 Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Kódování LZW Princip metody 3/3 Algoritmus dekomprese LZW 1 načti první kód C1 ze vstupu a najdi k němu ve slovníku slovo w1 2 načti kód C2 ze vstupu 3 vypiš w1 na výstup 4 pokud C2 není ve slovníku přidej do slovníku slovo w1 K1 , kde K1 je první znak w1 5 pokud C2 je ve slovníku najdi slovo w2 odpovídající C2 přidej do slovníku slovo w1 K2 , kde K2 je první znak w2 6 C2 → C1 , w2 → w1 a jdi na 2 Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Kódování LZW - příklad Předpoklady znaky v datech jsou jen velká písmena anglické abecedy na začátku je ve slovníku 26 písmen + znak # (ukončení zprávy) na začátku používáme 5-bitový kód # A B C .. . Z = = = = 00000 00001 00010 00011 = = = = 0 1 2 3 = 11010 = 26 kódujeme řetězec TOBEORNOTTOBEORTOBEORNOT# Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Kódování LZW - příklad Kódování TOBEORNOTTOBEORTOBEORNOT# Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Kódování LZW - příklad Dekódování TOBEORNOTTOBEORTOBEORNOT# Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Další varianty a vylepšení LZ77 LZ78 - upravený LZ77 s predikcí LZC - kontroluje efektivitu komprese, při klesající efektivitě smaže slovník DEFLATE - kombinace LZ77 a Huffmanova kódování (velmi populární: zip, gzip, PNG) LZMA - efektivní algoritmus použitý v programu 7zip LZX - modifikace používaná v souborech „cabinet“ a „MS compressed HTML“ LZJB - souborový systém ZFS ... Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Obsah 1 Úvod 2 Reprezentace barvy 3 Kódování a komprese dat 4 Formáty pro ukládání obrazu 5 Komprese videa Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Přehled populárních formátů 1/4 BMP (Windows Bitmap) - jednoduchý formát původně pro OS/2 a Windows 3.0 nekomprimovaná data v různých barevných hloubkách hlavička + sekvenčně po řádcích uložené hodnoty barev pixelů PNM (Portable AnyMap) - formát podobný BMP, dobře zdokumentovaný v manuálových stránkách UNIXu hlavička uložená vždy v ASCII začíná „magickým číslem“ rozlišuje typ typy: monochromatický (PGM), barevný (PPM), oba v binární i ASCII (!!) formě snadno lze naprogramovat vlastní funkce pro čtení / zápis před vykreslením nutné provést gama korekci, jinak bude obrázek vypadat tmavší PCX - jeden z nejstarších formátů, používá kompresi RLE Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Přehled populárních formátů 2/4 GIF (Graphics Interchange Format) omezení na 256 barev používá LZW kompresi umožňuje ukládat sekvence snímků (animace vhodné např. pro webové stránky) typ snímku (rozdílový snímek, plný snímek) časování podporuje průhlednost (jedna barva definována jako průhledná) textové informace Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Přehled populárních formátů 3/4 TIFF (Tag(ged) Image File Format) původně pro ukládání černobílých snímků (ze scanneru, faxu) - kódování G42D nyní ve verzi 6.0 vysoce flexibilní kontejnerový formát, standardizován ISO 12234-2, ISO 12639 soubor obsahuje adresáře (IFD, Image File Directory) a bloky obrazových dat IFD je tabulka popisků (tag, nověji field) určující typ dat a adresu začátku datového bloku =⇒ v jednom souboru i více obrázků (stránek) každá stránka navíc může být komprimována jinak PackBits, JPEG (!), ... RGB, indexovaná barva ukládání po dlaždicích =⇒ lze zpracovávat jen část obrazu ... nedostatek podpory všech možností TIFFu v (starším) softwaru =⇒ Thousands of Incompatible File Formats Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Přehled populárních formátů 4/4 PNG (Portable Network Graphics) relativně nový formát, zaměřen na web standardizován (ISO) bezztrátová komprese na bázi LZ77 ukládání pixelů po bezztrátovém předzpracování (none, Sub - rozdíl oproti pixelu vlevo, Up - rozdíl oproti pixelu na předchozím řádku, Average - průměr pixelu a dvou sousedů, Paeth - složitější průměrování) umožňuje dvourozměrné prokládání (nejprve přenese např. 1 pixel z každé matice 2 × 2) =⇒ umožňuje náhled obrázku před stažením všech dat z webu ukládá True Color RGBA (včetně průhlednosti) Prokládání Adam7 Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Formát JPEG JPEG - Joint Photographic Experts Group, 1991 standardizován (ISO) ztrátová komprese s nastavitelnou úrovní (kvalitou) vhodné pro fotografie a další složité obrázky, kde skoro žádné dva pixely nemají stejnou barvu nevhodné pro obrázky s nižším barevným rozlišením rozmazává ostré přechody, nejviditelněji na hranicích souvislých barevných ploch praxe: při nastavení kvality na „75%“ není většinou pouhým okem poznat rozdíl od originálu, kompresní poměr je přitom cca 1 : 20! kromě obrázku obsahuje metadata (EXIF informace) Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Formát JPEG Komprese JPEG 1/4 1. Transformace barev převedení barev do prostoru YCB CR na změny jasové složky Y je člověk citlivější než na změny odstínů =⇒ kanály Y a CB CR se zpracovávají odděleně, CB CR lze více komprimovat 1 byte na kanál 2. Redukce barev (ztrátová, ale ztráta nevýznamná) průměrování hodnot CB CR sousedních pixelů: 2h1v - průměrování sousedních dvojic v řádku (2 horizontálně, 1 vertikálně) =⇒ redukce ze 6 na 4 byty 2h2v - průměrování čtveřic (2 horizontálně, 2 vertikálně) =⇒ redukce ze 12 na 6 bytů Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Formát JPEG Komprese JPEG 2/4 3. DCT: data v každé barevné složce rozdělena do čtverců 8 × 8 pixelů každý čtverec podroben dopředné diskrétní kosinové transformaci (DCT) - podobná diskrétní Fourierově transformaci 7 7 XX (2x + 1) uπ (2y + 1) v π 1 C (u) C (v ) f (x, y ) cos cos 4 16 16 x=0 y =0 1 √2 pro t = 0 C (t) = 1 jinak F (u, v ) = Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Formát JPEG Komprese JPEG 2/4 3. DCT: data v každé barevné složce rozdělena do čtverců 8 × 8 pixelů každý čtverec podroben dopředné diskrétní kosinové transformaci (DCT) - podobná diskrétní Fourierově transformaci pozn: zpětná (inverzní) transformace: 7 f (x, y ) = 7 (2x + 1) uπ (2y + 1) v π 1XX C (u) C (v ) F (u, v ) cos cos 4 16 16 u=0 v =0 F (u, v ) je koeficient v rozkladu f do kosinových vln Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Formát JPEG Komprese JPEG 3/4 výsledkem je matice 8 × 8 neceločíselných koeficientů vlevo nahoře tzv. DC člen - určuje konstantní (neperiodickou) složku v datech je roven osminásobku průměru celé původní matice ostatní členy jsou tzv. AC členy, jejich vliv klesá se vzdáleností od DC členu 4. Kvantizace: (ztrátová) matice koeficientů se po prvcích vydělí tabulkou kvantizačních koeficientů a výsledek se zaokrouhlí na celá čísla prvky v kvant. tabulce rostou se vzdáleností od levého horního rohu =⇒ potlačují se méně významné AC členy, po zaokrouhlení vyjdou rovny nule Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura Formát JPEG Komprese JPEG 4/4 standardní kvant. tabulka určena pro kvalitu cca 75% uživatel určí kvalitu Q v rozsahu od 0 do 100% skutečně použitá kvantizační tabulka vznikne přepočítáním standardní tabulky nepřímo úměrně ke Q použitá tabulka se uloží do souboru spolu s obrázkem (nutné pro dekompresi) čím nižší kvalita, tím více AC členů je po kvantizaci rovno 0 5. Kódování (bezztrátové) matice 8 × 8 se zakóduje Huffmanovým kódováním s využitím faktu, že méně významné AC členy jsou obvykle rovny nule DC členy jsou zapisovány zvlášt’ (ukládány relativně - jen rozdíly oproti DC v předchozím bloku 8 × 8) samostatný zápis DC =⇒ umožňuje rychle generovat náhled obrázku s 81 -rozlišením v každém směru Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Schéma komprese Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Formát JPEG Schéma zápisu DC členů a řazení AC členů v matici před kódováním Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad: DCT, kvantování, rekonstrukce Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Formát JPEG Příklad 1 - fotografie Originál BMP 804 × 534, 1288 kB (PNG 882 kB) Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 1 - fotografie JPEG 75%, 122 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 1 - fotografie JPEG 50%, 80 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 1 - fotografie JPEG 25%, 49 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 1 - fotografie JPEG 5%, 13 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Formát JPEG Příklad 2 - text Originál BMP 1182 × 605, 2147 kB (PNG jen 109 kB!) Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 2 - text JPEG 75%, 176 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 2 - text JPEG 50%, 125 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 2 - text JPEG 25%, 93kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Formát JPEG Příklad 2 - text JPEG 5%, 40 kB Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Obsah 1 Úvod 2 Reprezentace barvy 3 Kódování a komprese dat 4 Formáty pro ukládání obrazu 5 Komprese videa Komprese videa Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Komprese videa mnoho formátů MPEG-1, MPEG-2 (Motion Picture Experts Group) sekvence klíčových (úplných) a rozdílových snímků ztrátová komprese pro obraz i zvuk (MP3, AAC) formát MPEG-4 pokročilá komprese videa definice titulků pohyb 3D objektů, pohyb kamery animace lidského obličeje a popis jeho výrazu (talking head) obvykle implementována jen komprese videa (DivX, XviD, H.264) další formáty: ASF, QuickTime, Flash FLV, ... Literatura Úvod Reprezentace barvy Kódování a komprese dat Formáty pro ukládání obrazu Komprese videa Literatura I. Vajda: Teorie informace. Vydavatelství ČVUT, Praha, 2004. ISBN: 80-01-02986-7 Žára, Beneš, Sochor, Felkel: Moderní počítačová grafika. Computer Press, 2005. ISBN: 80-251-0454-0 Literatura
Ukládání a komprese obrazu
Fraktální komprese
Copyright © prosinec 2001 Martin Přikryl
Obsah
Historie
Fraktální kódování je matematický postup používaný ke kódování bitmapových obrazů reálného světa jako množiny matematických dat, která vyjadřují fraktální vlastnosti obrazu. Fraktální kódování vychází ze skutečnosti, že všechny přirozené a většina umělých obrazů obsahují nadbytečné informace ve formě podobných, opakujících se vzorů, tzv. fraktálů.
Fraktál je struktura tvořená podobnými vzory a obrazy, které se vyskytují v mnoha různých velikostech. Pojem fraktál poprvé použil matematik IBM Benoit Mandelbrot při popisu opakujících se vzorů, tento jev pozoroval v mnoha různých strukturách. Forma těchto vzorů se jevila téměř identická při jakékoli velikosti a vyskytovala se přirozeným způsobem ve všech věcech. Mandelbrot rovněž zjistil, že tyto fraktály lze vyjádřit matematicky a že je lze vytvořit pomocí velmi malých konečných algoritmů a dat. Svá zjištění popsal v knize "Fraktální geometrie přírody" v roce 1977. V této knize uvedl tuto myšlenku: "Tradiční geometrie se svými přímými čárami a hladkými povrchy nepřipomíná geometrii stromů, mraků a hor. Zatímco fraktální geometrie se svými zavinutými pobřežími a detaily ad infinitum ano. Touto teorií získal svět počítačů nástroj k vytváření umělých a přesto reálně vypadajících tvarů.
Dalším důležitým dílem byla práce Johna Hutchinsona z roku 1981, kde popsal nové odvětví matematiky dnes známé jako "Iterated Function Theory". Na toto dílo navázal Michael Barnsley s knihou "Fractals Everywhere". V ní definoval "Iterated Functions Systems" a jaké vlastnosti musí mít, aby pomocí nich bylo možné reprezentovat obraz.
Z těchto teorií vyplynula zajímavá možnost. Jestliže je jednom směru možné fraktálovou matematikou popsat přirozeně vypadající obraz, nebylo by ji potom také možné, v opačném směru použít ke kompresi obrazu? Popis obrazu pomocí IFS je znám jako inverzní problém. Tento problém je stále nevyřešen.
Barnsley v roce 1987 založil společnost "Iterated Systems Incorporated" a nechal si patentovat vlastní postup na řešení inverzního problému. Zároveň v časopisu BYTE publikoval své výsledky a uvedl i několik příkladů obrazů zkomprimovaných pomocí IFS, u kterých dosáhl kompresního poměru 10 000:1. Později ovšem připustil, že komprese každého z nich trvala okolo 100 hodin na jednom z nejrychlejších počítačů té doby. A to dokonce s nezbytnou asistencí člověka.
V roce 1988 Barnsleyho student Arnauld Jacquin modifikoval IFS. Změna spočívala v tom, že se již v obrazu nehledaly věrné kopii obrazu celého, ale pouze jeho částí. Nový postup byl pojmenován Partitioned IFS. Změnou byla umožněna plná automatizace komprimačního algoritmu, ovšem na úkor kompresního poměru. Ten se nyní pohyboval v rozmezí 8:1 až 50:1. Přesto jsou všechny současné fraktálové kompresní algoritmy založeny na Partitioned IFS. I tento nový postup byl patentován Barnsleym.
Vlastnosti fraktální komprese
Ztrátová Nehledá se věrná kopie obrazu (části obrazu), stačí přibližná. Z toho plyne, že degradace obrazu, která vzniká je jiného druhu než u běžných kompresních algoritmů (JPEG). Díky fraktálním složkám obrazu se změny jeví mnohem přirozeněji. Důsledkem toho jsou obtíže při srovnání úspěšnosti fraktální komprese oproti například JPEGu. To proto, že se dá jen těžko porovnat kvalita obrazu zkomprimovaného při stejném kompresním poměru oběma algoritmy, vzhledem k tomu že ztráta kvality se projeví odlišně. Asymetrická Komprese obrazu trvá několikanásobně déle než dekomprese. Fraktální interpolace Dekomprimovaný obraz má znaky fraktálu. Je možné ho zvětšovat prakticky donekonečna a stále se objevují nové detaily (neobsažené v původním komprimovaném obraze, tj. dopočítané). Konstantní poměr ztráty kvality a míry komprese Na rozdíl od JPEG klesá kvalita obrazu po kompresi víceméně lineárně s růstem kompresního poměru. Nezávislá na barevné hloubce obrazu Velikost dat po kompresi je stále stejná bez ohledu na počet bitů na pixel v komprimovaném obraze. Z toho plyne, že kompresní poměr se zlepšuje lineárně s počtem bitů na pixel. Vhodné na fotografie Fraktální komprese dosahuje lepších výsledku (kvality) při kompresi přirozených obrazů (fotografií) než obrazů umělých (kreseb, náčrtků, počítačové grafiky). Patentovaná
Klasický přístup
Princip
IFS se připodobňuje k Mnohonásobné zmenšovací kopírce (MZK). MZK má oproti běžné kopírce tyto vlastnosti:
Má několik sad čoček, které vytvářejí několik překrývajících se kopií originálu. Každá sada čoček zmenšuje velikost originálu. Kopírování probíhá iterativně. Vstupem do dalšího cyklu je výstup předchozího. Vstupem může být libovolný obraz.
Schéma Mnohonásobné zmenšovací kopírky
V klasickém IFS se v obraze vyhledává sebepodobnost mezi celým obrazem a jeho zmenšenými kopiemi v něm. V běžných obrazech, je ale možné nalézt tuto podobnost jen zřídka. Na fotografii krajiny mohou být stromy, tráva, kopce a obloha. Nalézt v obraze zmenšený vzor, obsahující všechny tyto součásti je v podstatě nemožné. Tento problém narůstá, pokud jsou na fotografii lidé nebo budovy.
Dalším faktorem je, že klasický přistup neobsahuje postupy, jak se vypořádat se světelnou intenzitou a barevnými vlastnostmi v různých částech obrazu.
Ke klasickému IFS lze říci, že je to zajímavý a nový přístup ke kompresi obrazu, ale v praxi bohužel nepoužitelný. Úspěchů lze dosáhnout jen s uměle vytvořenými obrazy, dva nejznámější jsou "Sierpinského trojúhelník" a "Spleenwortova kapradina".
Spleenwortova kapradina
Sierpinského trojúhelník
Fraktálový strom
Teoretické základy
Tato kapitola je k dispozici jen ve verzi pro stažení (ve formátu Word).
Současný přístup
Doménové a řadové bloky
Jak již bylo řečeno, všechny současné fraktální kompresní algoritmy vycházejí z Partitioned IFS. Tato metoda obchází nemožnost nalezení věrné zmenšené kopie celého obrazu tím, že hledá jen kopie jeho částí. Vychází z předpokladu, že když rozdělíme obraz na celky s podobnými vzory (tedy například na oblohu, trávu, stromy), bude jednodušší nalézt podobnosti mezi těmito celky a jejich částmi. V praxi se toto provádí rozdělením obrazu na pravidelné bloky a hledání jejich větších kopií kdekoliv jinde v obrazu. Znázornění postupu viz obrázek.
Hledání podobnosti mezi doménovými a řadovými bloky obrazu
Při kompresi se obraz rozdělí na pravidelné řadové bloky (range blocks), které se nepřekrývají (pravá strana schématu). Ke každému z těchto bloků je dohledáván nejpodobnější doménový blok (levá strana schématu). Doménové bloky se mohou překrývat a nemusí dohromady pokrývat celou plochu obrazu.
Poznámka 1: Doménové i řadové bloky jsou vybírány ze stejného obrazu, oddělené znázornění na schématu je jen pro větší přehlednost.
Poznámka 2: Doménové bloky jsou zpravidla větší než řadové, to zajistí konvergenci obrazu při dekompresi. Pokud by většina doménových bloků nebyla větších než jim odpovídající řadové, probíhala by dekomprese donekonečna, resp. by byla nemožná. Z tohoto důvodu většina kompresních programů ani neumožňuje přiřazení doménového bloku k řadovému bloku, který je větší.
Tvar bloku může být v podstatě libovolný, v praxi se ale většinou využívá čtvercový tvar. Velikost doménového bloku je celočíselným násobkem velikosti řadového bloku, nejčastěji dvojnásobkem. Řadový blok mívá velikost 8×8 pixelů (příp. 4×4, 16×16, 32×32) a odpovídající doménový 16×16 (resp. 8×8, 32×32, 64×64).
Úpravy doménových bloků
Aby se zvýšila pravděpodobnost nalezení podobného doménového bloku, každý z nich se různými metodami upravuje. Nejběžnějšími úpravami je změna jasu a kontrastu pixelů bloku, dále osm symetrických transformací. Tyto transformace jsou následující:
Otočení o 0 stupňů (resp. žádná transformace) Otočení o 90 stupňů Otočení o 180 stupňů Otočení o 270 stupňů Otočení podle horizontální osy Otočení podle vertikální osy Otočení podle první diagonály Otočení podle druhé diagonály
Výhoda plynoucí z použití symetrických transformací
Víceúrovňové párování
Jednoduchý postup párování řadových bloků s doménovými má tu nevýhodu že nebere v úvahu obsah bloku. To neumožňuje zefektivňovat přiřazení podle úrovně detailů v bloku obsažených. Pokud blok neobsahuje žádné detailní struktury (například obloha, tráva...), je běžně možné nalézt podobný pár i při velikosti řadového bloku 32×32 pixelů. Naopak v blocích s velmi detailními strukturami by bylo vzhledem k zachování kvality obrazu hledat páry k řadovým blokům o velikosti 4×4 pixely.
Nejčastějším řešením tohoto problému je hierarchické párování. Při jeho použití se jako základní velikost řadového bloku použije např. 16×16 pixelů. K bloku této velikosti se dohledá nejpodobnější pár. Pokud se přesnost shody vejde do daného intervalu je vyhledaný pár přijat. Pokud ne, rozdělí se blok na čtyři stejně velké bloky (8×8 pixelů) a ke každému zvlášť je hledán doménový blok. Tímto způsobem je možné postupovat iterativně na stále menší bloky. Nejčastější počet používaných úrovní jsou dvě (bloky o velikosti 8×8 a 4×4) a tři (16×16, 8×8 a 4×4).
Existují dvě varianty hierarchického párování, úplné a částečné. Při použití první se blok vždy dělí na čtyři části a ke každé z nich se dohledává nový pár. Při použití druhé složitější varianty, se dopočítá přesnost shody pro každou ze čtyřech částí bloku a pár se dohledává jen k těm, kde není splněna daná shoda. Je zároveň nutné si zapamatovat i párový doménový blok pro celý rozdělený řadový blok, což u jednodušší varianty není nutné, protože čtyři podbloky pokryjí celou jeho plochu.
Původní "Lenna"
Úplné hierarchické členění
Alternativní přístupy k řešení dělení bloku je dělení jen na poloviční obdélníkové části nebo dělení podle diagonál na trojúhelníky. Tyto alternativy ale nepřinesly zlepšení kvality komprimovaného obrazu.
Urychlení kompresního algoritmu
Vyhledávání nejpodobnějšího doménového bloku ke každému řadovému postupným vzájemným porovnáváním je nejnáročnější částí algoritmu. Z tohoto důvodu vzniklo mnoho variant kompresního algoritmu, které se liší způsobem, jakým omezují počet prováděných porovnání a tím i urychlují kompresi.
Těžká hrubá síla
Tato metoda nijak neomezuje počet porovnání. Příklad: Máme obraz o velikosti 256×256 pixelů, řadový blok o velikosti 8×8 a doménový 16×16 pixelů. To nám dává (256/8)2=1024 řadových bloků, kterým je třeba dohledat nejpodobnější doménový blok. Při libovolném umístnění je doménových bloků (256-16+1)2=58 081. Pokud použijeme osm symetrických operací, je celkový počet porovnání, který je potřeba k nalezení všech přiřazení řadový-doménový blok, roven 1024×58 081×8=475 799 552 (475 miliónů).
Metoda "těžké hrubé síly" sice nalezne nejlepší přiřazení, ale pro svou časovou náročnost se nepoužívá. Uvádím ji zde jen pro srovnání jako horní hranici doby trvání. Každá z dále uvedených metod na jednu stranu urychluje kompresi, na druhou stranu snižuje kvalitu zkomprimovaného obrazu.
Lehká hrubá síla
Nejjednodušší způsob, jak omezit množství porovnání, je omezení možných poloh doménových bloků. Při porovnání se například uvažují jen bloky na sudých souřadnicích, což omezí počet srovnání na čtvrtinu oproti metodě "těžké hrubé síly". Omezení může samozřejmě být i rozsáhlejší.
Mimo urychlení doby komprese může tato metoda zvýšit i kompresní poměr, protože k uložení polohy doménového bloku ve výstupním souboru je třeba méně bitů. Při použití této úspory musí ovšem dekomprimační program vědět, jakým koeficientem uloženou polohu vynásobit.
Omezení prohledávané oblasti
Při hledání podobného doménového bloku se neprohledává celý obraz, ale jen určitá omezená plocha. Například jen okolí řadového bloku do určité vzdálenosti. Více sofistikované alternativy rozdělí obraz nejdříve na oblasti s podobnými vzory a následně prohledávají jen oblast, ve které leží daný řadový blok.
Spirála
Vyhledávání do spirály je určitou modifikací předchozí metody. Prohledávání se začne na souřadnicích, kde leží řadový blok. Dále se pokračuje ve spirále. V tomto případě se nehledá nejlepší pár, ale hledaní skončí v okamžiku, kdy je nalezen doménový blok s dostačující podobností.
Vyhledávání "na místě"
Tato metoda je stejně jako metoda "těžká hrubá síla" uváděna jen pro srovnání jako dolní mez dosažitelné doby vyhledávání párů. Jako párový doménový blok je vždy vybrán ten, který je na stejných souřadnicích jako řadový blok.
Kategorizace doménových bloků
Do této kategorie spadá mnoho různých metod. Pro všechny obecně platí, že se před započetím hledání párů rozdělí všechny doménové bloky do několika kategorií, případně ohodnotí podle určitého kritéria na spojité škále. Každý řadový blok se při prohledávání zařadí resp. ohodnotí stejným způsobem a dále se již porovnává pouze se stejně zařazenými doménovými bloky.
Jednou z nejjednodušších kategorizačních metod je rozdělení doménových bloků do jedné ze tří kategorií rozlišených podle struktury v bloku obsažené. V jedné skupině budou bloky se zřetelnou hranou, v další bloky s určitou strukturou (ale ne hranou) a v poslední bloky bez zřetelné struktury. U každého doménového bloku se také určí jeho zařazení do jedné z těchto kategorií a podobný doménový blok se již vyhledává pouze v rámci ní.
Další složitější používaná kategorizační metoda ohodnocuje každý blok na základě dvou kritérií: střední hodnoty úrovně šedi pixelů bloku a počtu dominantních barev v bloku. Tím se vytvoří dvourozměrná matice. Každý řadový blok se ohodnotí podle stejných kritérií. Dále se již prohledávají jen doménové bloky s hodnotami charakteristik v daném intervalu okolo hodnot řadového bloku. Tento algoritmus je obtížně implementovatelný, vzhledem k těžkostem při specifikaci charakteristik (definice "dominantní barvy" ...).
Jiná kategorizační metoda rozděluje doménové bloky do 72 kategorií a to na základě dvou charakteristik. Nejdříve je každý blok zařazen do jedné ze tří základních kategorií (viz obrázek). Zařazení se provádí tak, že se blok rozdělí na čtyři kvadranty a pro každý se spočítá střední hodnota hodnot pixelů. Každá kategorie má dané pořadí kvadrantů podle středních hodnot. Pokud nelze zařadit blok do žádné z nich hned, je to možné po aplikaci jedné z osmi symetrických transformací. Výsledkem je tzv. kanonická pozice. V rámci každé třídy se podle pořadí hodnot rozptylu rozdělí do dalších 4!=24 kategorií. Celkový počet tříd je tedy 3×24=72. Při hledání párů se prohledává již jen ta kategorie, do které by patřil daný řadový blok. Navíc již není nutné provádět symetrické operace, protože srovnávaný doménový i řadový blok jsou již v kanonické pozici.
Základní třídy. Barvy označují relativní střední hodnoty
Jako poslední bude popsána metoda, která do skupiny kategorizační spadá jen částečně. Tato metoda je specializována na použití s hierarchickým párováním. Nejdříve je pro každý blok na jednotlivých úrovních spočítán rozptyl a podle jeho hodnoty jsou bloky seřazeny. Potom jsou ze vzniklé škály vybrány jen bloky spadající do určitého intervalu, například podle následujícího klíče:
úroveň 64×64: všechny ze spodních 10% škály (hladké oblasti)
úroveň 32×32: polovina z horních 10% (hrany), polovina z intervalu 20-50%
úroveň 16×16: polovina z horních 10%, polovina z intervalu 50-80%
úroveň 8×8: všechny z horních 10%
Tento heuristický postup je založen na faktu, že velké bloky (64×64) většinou pokrývají oblasti bez znatelné struktury (obloha...) a malé bloky spíše místa s ostrými hranami.
Obecně
Některé uvedené metody lze vzájemně kombinovat. Například principem postupu "lehká hrubá síla" lze rozšířit každou z dalších uvedených metod. Další možností vylepšení je vyřazování duplicitních resp. velmi podobných doménových bloků z porovnávání.
Dekomprese
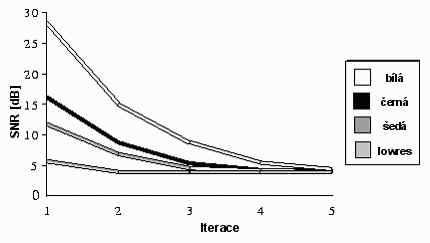
V porovnání s kompresí je dekomprese velmi rychlá a jednoduchá. Jako základ se použije libovolný obraz a na něj se iterativně aplikují uložená transformační pravidla. Vstupem do každého dalšího cyklu iterace je výstup předchozího. Již po dvou iteracích se objevují zřetelné detaily obrazu. Při osmibitové barevné hloubce je dekomprimace dokončena po přibližně 4 iteracích.
Jako výchozí obraz se obvykle používá jednobarevná šedivá plocha. S ní se dosahuje nejrychlejších výsledků, tj. obraz se stabilizuje po nejmenším počtu iterací. Ještě lepších výsledků lze dosáhnout pokud se jako výchozí použije méně kvalitní kopie cílového obrazu, ta ale většinou není dostupná. Transformační pravidla lze aplikovat na libovolný obraz, může jím být i zcela jiná fotografie. Tuto variantu jen uvádím jako zajímavost, v praxi nemá uplatnění, jen zvyšuje počet iterací potřebných k rekonstrukci obrazu.
Rekonstrukce obrázku "Lenna" na základě černé plochy
Počet iterací nutných k rekonstrukci obrazu. U obrazu "Lenna" byla jako výchozí použita černá plocha, u obrazu "San Francisko" byl jako výchozí použit jiný obraz "Ork"
Rekonstrukce obrázku "San Francisko" na základě jiného obrázku "Ork"
Počet iterací nutných k rekonstrukci obrazu v závislosti na použitém výchozím obrazu (lowres je méně kvalitní kopie stejného obrazu)
Kompresní poměr
Výpočet kompresního poměru, kterého lze dosáhnout popsanými metodami, uvedu na příkladu. Předpokládáme obraz s velikostí 256×256 pixelů s barevnou hloubkou 8 bitů. Velikost řadového bloku je 8×8 pixelů, doménový blok je 2× větší. Máme tedy 1024 řadových bloků, tj. 1024 transformací, které je nutné uložit do výstupního souboru. Do kolika bitů se vejde informace o jedné transformaci?
Počet bitů potřebných k uložení informací o jedné transformaci
Horizontální souřadnice 8 (6) bitů Vertikální souřadnice 8 (6) Použitá symetrická operace 3 Faktor úpravy kontrastu 5 (8) Faktor úpravy jasu 6 (8) Celkem 30 bitů
Při 30 bitech na jednu transformaci je celková velikost výstupních dat 30×1024=30 730 bitů. Velikost dat vstupního obrázku je 256×256×8=524 288 bitů. Kompresní poměr je tedy 524 288/30 730=17,06. Tato hodnota se může měnit vzhledem k velikosti řadového/doménového bloku a to jak nahoru tak dolů. Dále ji převážně pozitivně ovlivňuje použití hierarchického párování. Kompresní poměr zlepšuje použití principu "lehké hrubé síly". S růstem velikosti obrazu roste i počet bitů nutných k uložení pozice doménového bloku, tedy klesá kompresní poměr. Jak již bylo uvedeno, velikost výstupních dat není ovlivněna barevnou hloubkou vstupního obrazu. Z toho plyne, že s růstem barevné hloubky se zlepšuje i kompresní poměr. Pokud by náš modelový obrázek měl barevnou hloubku 24 bitů (True color), byla by velikost vstupních dat 256×256×24=1 572 864 bitů, velikost výstupních dat se nezmění, kompresní poměr tedy bude 1 572 864/30 730=51,18.
Srovnání s JPEG
Srovnání s kompresí JPEG je obtížné, vzhledem k odlišnosti chyb vnesených do komprimovaného obrazu těmito algoritmy. Obecně ale ne vždy platí, že zkreslení obrazu fraktální kompresí je přirozenější než zkreslení kompresí JPEG.
Obecně lze říci, že pro nízké kompresní poměry dosahuje JPEG lepší kvality než fraktální komprese, pro větší kompresní poměry je tomu naopak. Za zlomový bod se považuje kompresní poměr 1:10-1:40 (liší se podle obsahu obrazu). To podporuje i fakt, že po tomto bodě obsahují obrazy komprimované JPEG tolik šumu, že jsou v podstatě nepoužitelné. Na rozdíl od JPEG dochází u fraktální komprese ke zkreslování pozvolna s růstem kompresního poměru.
Porovnání fraktální komprese a JPEG pro obrázek "Lenna"
Porovnání fraktální komprese a JPEG pro obrázky "Bird" a "Cameraman"
Použití
Fraktální komprese se hodí zejména na kompresi přírodních obrazů. Velmi špatných výsledků je dosahováno při práci s obrazy, které obsahují text a kresby. Tyto části obrazu jsou po kompresi deformovány, někdy dokonce úplně zmizí, to je typické hlavně pro přímé čáry, které směřují diagonálně k hranám řadových bloků.
Kvalita komprese pro různé typy obrazu
Typ obrazu Nízká komprese Vysoká komprese text, kresby nízká nízká počítačová grafika nízká až dobrá nízká až průměrná fotografie dobrá velmi dobrá
Jednou ze zajímavých vlastností je "fraktální interpolace". Používaný počet iterací při dekompresi je dán jen rozlišovací schopností obrazovky (nebo jiného zařízení). Je ale možné provádět další cykly. Od určitého okamžiku se v dekomprimovaném obraze objeví detaily, které v původním obraze nebyly obsaženy. Tomuto jevu se říká fraktální interpolace. Na rozdíl od klasické interpolace používané k zvětšování bitmapových obrazů, se u fraktální interpolace neobjevují umělé čtverhranné útvary.
Použitá literatura